The Context Engineering Playbook: Achieving High-Fidelity, Brand-Consistent LLM Responses

I. The Strategic Mandate: Deconstructing the Generic Content Problem
The pursuit of high-quality, brand-consistent content from Large Language Models (LLMs) requires a fundamental shift in strategy. The default output of an LLM is a statistically determined average of its vast training data, resulting in a pervasive phenomenon known as "tone flattening" or "genericity." Overcoming this default state necessitates rigorous architectural controls—a discipline termed Context Engineering.
A. Defining "Tone Flattening": The Statistical Default
LLMs function by predicting the next sequence of words most likely to follow from the previous text.[1]
Because these models are trained on immense corpora of public data, their highest-probability outputs tend toward the mean, producing a "smooth, vaguely professional, slightly generic voice".[2]
This result is not a flaw in the model; it is the statistical center of the training distribution. When organizations deploy AI without sufficient steering mechanisms, the brand's unique stylistic "edges" are inevitably sanded off, leading to content that is recognizable as AI-generated and lacks distinctive character.To produce content that aligns with a specific brand ethos, the prompt architecture must actively prevent the inclusion of artifacts inherent to the model's training. This requires identifying and prohibiting common LLM anti-patterns, which often manifest as unnatural repetition of certain words, awkward idioms, and generic filler phrases.[3]
Specific phrases, such as "When it comes to," "It's important to note," or "In today's world," are frequently introduced by the AI to pad text or maintain a neutral tone. These phrases signal padding rather than substance and must be explicitly governed to ensure output quality.[3]
B. The Evolution from Prompt Engineering to Context Engineering
In the early stages of large language model adoption, focus was placed primarily on Prompt Engineering—the art of finding the right words and phrases within a single input to guide the model.[1, 4]
While this is a foundational skill, modern, high-quality content production requires scaling beyond single-turn prompt optimization.
Context Engineering represents the natural progression of this discipline. It involves managing the holistic state of the LLM—the optimal configuration of all available tokens—to consistently achieve a desired outcome.[4]
This includes dynamic elements like user history, workflow data, external knowledge bases, and the explicit instructions provided. The engineering challenge is optimizing the utility of these tokens against the inherent constraints of the LLM architecture.
The observation that generic output is the model's highest-probability, lowest-risk response has profound implications for strategy. If a desired brand voice is distinct, the content engineer must input high-signal stylistic information (precise examples and explicit prohibitions) to exert enough directional stimulus to force the model away from its statistical center.[2]
Therefore, effective LLM steering must be viewed as providing sufficient context and instruction priority to overcome the model's intrinsic neutrality.
C. The Foundational Role of the System Prompt
The System Prompt is the cornerstone of achieving consistent LLM behavior. Unlike User Prompts, which are task-specific and dynamic, the System Prompt serves as the "backbone" of the AI’s behavior, setting the overall framework for how the AI operates across all interactions.[5]
The System Prompt acts as the LLM's behavioral contract or "job description and guidelines".[6]
It is typically set once and remains consistent, defining the model's foundational role, tone, and global constraints. For instance, a system prompt for a content AI might include instructions like, "You are a witty, senior technical writer. Always maintain a professional yet subtly humorous tone. Avoid jargon where plain language is possible".[6]
This mechanism establishes the global guardrails necessary for enforcing brand voice at scale.
II. Architecture of the High-Fidelity Prompt Scaffold
Achieving high-quality, non-generic responses requires prompts that are structured, modular, and designed for maintainability. This move prompts creation from an intuitive practice toward a formalized, architectural discipline.
A. System Prompt Design: Separation of Concerns (SoC)
Effective system prompt design leverages the principle of Separation of Concerns (SoC), analogous to separating HTML, CSS, and JavaScript in software architecture.[7]
This modular approach enhances flexibility and scalability. By dividing the system prompt into distinct sections (Identity, Constraints, and Examples), adjustments to one component are less likely to destabilize others.
1. Defining Role and Persona
The definition of the AI’s identity must go beyond a simple functional designation.
• Role Prompting defines the function of the LLM, such as "Pretend you're a JSON structure sentiment classifier" or "Talk like a lawyer".[8] This establishes the expected knowledge domain and behavioral function.
• Persona Specification defines the personality and stylistic traits—characteristics such as friendliness, formality, humor, or authority.[9] This is the essential layer for brand consistency, influencing how the response is conveyed, not just what is conveyed. A well-defined persona fosters consistent, relatable communication.[9]
This framework implies that the System Prompt (the behavioral 'Model') defines the identity and global constraints (the 'CSS/JS logic'), while the User Prompt (the 'View' and 'Controller') handles the dynamic, specific task. This architectural separation significantly simplifies debugging adherence issues; if the style fails, the engineer isolates the System Prompt; if the task execution fails, the focus shifts to the User Prompt.
2. Avoiding Prompt Contradictions
A common failure point in complex prompt design is the introduction of conflicting instructions, which degrade the model's adherence and reliability. For example, setting an instruction in one section to "Be empathetic and conversational" while later including a constraint to "Avoid expressing emotions or personal tone" creates an internal conflict that the LLM may resolve unpredictably.[7]
Maintaining logical consistency throughout the System Prompt is paramount to ensuring robust model behavior.
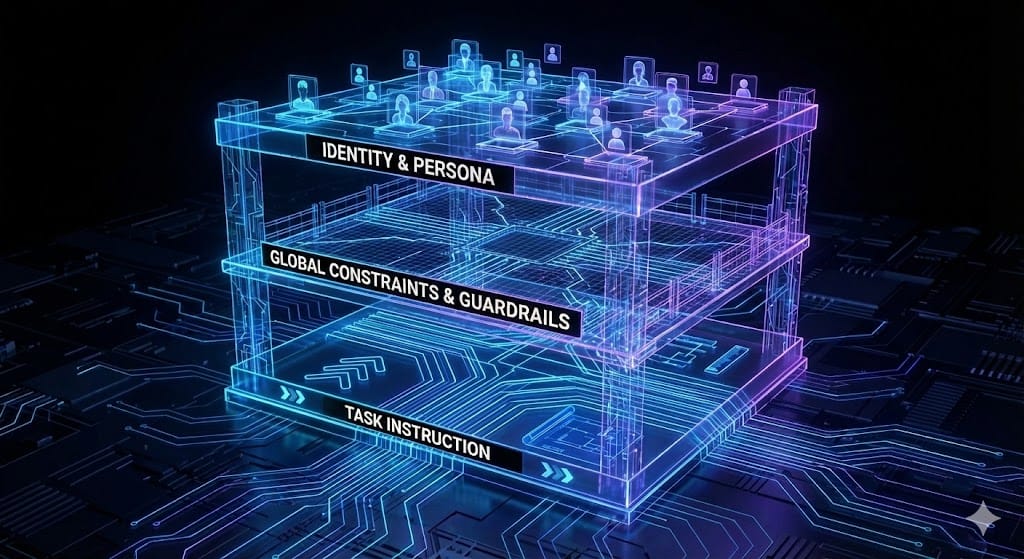
The core principles of an enterprise-grade prompt scaffold are summarized in the following table, detailing the required modularity.
The Optimized Prompt Scaffold Architecture
Component | Role (SoC) | Purpose | Example Content |
System Identity | Model | Defines the Role and Persona (Function + Personality). | You are a Senior Content Strategist for Acme Corp. Your tone is Professional yet Wit-driven. |
Global Constraints | Model | Sets Tone, Brand Voice rules, and Safety/Compliance guardrails. | Always maintain a Professional yet Playful tone. Never disclose internal budget figures. |
Negative Guardrails | Model | Explicitly prohibits generic or off-brand language/structure. | No filler phrases ("In today’s world"), no rhetorical questions, avoid passive voice, no clickbait CTAs. |
Few-Shot Examples | View/Controller | Provides structured templates for required output style and format. | [Good Example: Input-Output Pair demonstrating desired structure and tone]. |
Task Instruction | Controller | The dynamic, specific command for the current interaction. | TASK: Summarize the provided Q3 financial report focusing only on ESG metrics in 3 bullet points. |
B. Advanced Prompting Techniques for Quality and Reasoning
Beyond basic instructions, advanced techniques must be layered into the prompt structure to enhance reasoning capabilities and reduce variability.
1. Few-Shot Learning for Conditioning
Successful prompts often rely on few-shot learning, which involves providing one or more examples of the desired model behavior, typically as input and output pairs.[1]
Although this does not permanently change the model's weights, it conditions the LLM to respond as desired for the current inference.[1]
Few-shot examples are critical for demonstrating the target structure, style, and word choices the brand wishes to replicate.[10] This method is essential for stylistic consistency, especially in scenarios where gathering large amounts of labeled data for fine-tuning is impractical.[11]
2. Chain-of-Thought (CoT) Prompting
Chain-of-Thought (CoT) prompting is a technique that instructs the model to break down a complex task and present its internal steps and reasoning explicitly.[1, 12] This approach substantially improves the reliability and performance of LLMs on complex tasks, moving beyond simple input/output generation to transparent, auditable decision-making.[12]
3. Combining Techniques for Nuance
The most powerful outputs are generated by prompts that integrate multiple techniques into a cohesive whole.[13] For instance, combining Role Prompting (defining the persona) with Instruction Prompting (defining the task) and Few-Shot Prompting (demonstrating the style) results in responses that are significantly more nuanced and accurate.[13] This combination is particularly effective for creative content generation or complex data classification tasks.
4. The Solo Performance Prompting (SPP) Trend
An emergent technique is Solo Performance Prompting (SPP), which leverages the concept of cognitive synergy within a single LLM.[14] SPP dynamically identifies and simulates * multiple, fine-grained personas*—such as a "Domain Expert" and a "Cognitive Synergist"—based on the task input.[14] This architectural approach has been shown to improve problem-solving, enhance creative writing, and effectively reduce factual hallucination compared to standard CoT methods.[14]
A crucial observation regarding advanced scaffolding techniques is that they are highly dependent on the capability of the underlying model. Research on SPP, for example, demonstrated that the benefit of cognitive synergy only emerged in highly capable models like GPT-4, and not in less advanced versions like GPT-3.5-turbo or Llama2-13b-chat.[14] This confirms that organizations must strategically match the complexity of their prompt strategy (e.g., CoT, SPP, Tree of Thoughts) to the proven sophistication of the selected foundation model; advanced architecture will fail if the model lacks the requisite capacity to simulate complex internal dynamics.
III. Engineering Brand Voice: Techniques for Non-Generic Content
Overcoming tone flattening requires a two-pronged approach: explicitly defining the desired style (positive space) and aggressively filtering out the unwanted style elements (negative space).
A. Few-Shot Learning for Stylistic Integrity
Few-shot examples are not just for format; they are the primary mechanism for transferring the brand’s emotional tone and stylistic integrity to the LLM.[10]
1. The Template Mechanism
Examples function as explicit templates, demonstrating the required tone, structure, word choice, and desired response length.[10] The process of selection is crucial: examples must be directly relevant to the task and clearly reflect the precise emotional tone targeted (e.g., "professional yet approachable").[10]
2. Strategic Placement and Contrast
The placement of examples within the prompt influences the model's application of the style. The sequence must ensure the LLM understands the context first, observes the stylistic pattern second, and then applies the pattern to the specific task effectively. Best practice dictates placing examples after general instructions but before the specific task.[10] Furthermore, defining boundaries is critical. Including examples of bad or off-brand content alongside preferred examples can clarify the model's restrictions and desired boundaries.[10]
B. The Power of Negative Prompting as a Brand Guardrail
Negative prompting is an essential, often underutilized, tool for content governance. While commonly used in visual generation to exclude elements like "blurry" or "no cartoon style" [15, 16], its application in textual governance is vital for eliminating generic language.A negative prompt explicitly tells the AI model to downplay or remove specific features, reducing the weight of those unwanted elements in the token generation process.[16] This guides the model’s attention, highlighting positive requirements while muting distractions.[16]
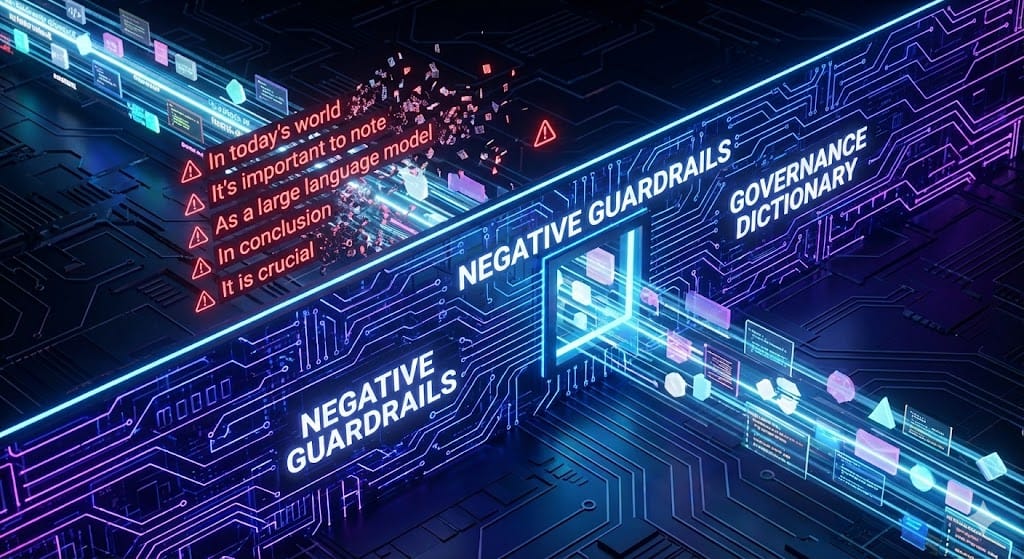
1. Governance Dictionary for Text
Organizations must develop a centralized negative prompt dictionary focused on linguistic anti-patterns that define generic AI output. This acts as a hard filter on token selection. Examples of textual guardrails that improve output realism and brand voice include prohibiting:
• Stylistic Flaws: “Excessive formality, robotic language, unnatural phrasing, overly long paragraphs, excessive flattery”.[17]
• Business Jargon: “Clickbait-style CTA, exaggerated claims, overly promotional, repetitive phrases, generic buzzwords, marketing-style language”.[18]
• Report Flaws: “Unsubstantiated claims, casual language, excessive adjectives, vague conclusions, unnecessary storytelling, unsupported opinions”.[18]
The strategic importance of negative prompting is evident in its ability to enforce compliance, even when models struggle with Instruction Adherence. A model might internally acknowledge a style guide but still inject genericisms. Negative prompting acts as a forceful, explicit mechanism to suppress the tokens associated with generic language, thereby increasing the certainty that the final output adheres to the brand's governance rules (Instruction Adherence).[19] This helps prevent the AI from defaulting to its high-probability, generic center.
IV. Grounding Responses with Retrieval-Augmented Generation (RAG)
Achieving brand quality requires generating content based on authoritative, proprietary information—not just the LLM’s general knowledge. Retrieval-Augmented Generation (RAG) is the mandatory architectural technique for grounding responses in enterprise data, ensuring relevance and mitigating the risk of factual hallucination.
A. RAG Architecture and Operational Context
RAG is a grounding technique that enriches the LLM by referencing an authoritative knowledge base (e.g., internal documents, style guides, policy manuals) outside of its original training data.[20]
The RAG process operates through a specific pipeline: a user query is received and converted into a numerical vector (embedding). This embedding is used to retrieve semantically similar documents (context) from a vector database. The retrieved content is then injected into the LLM prompt as context, enabling the model to craft a response informed by actual retrieved information.[21]RAG offers significant advantages over fine-tuning for dynamic knowledge needs. While fine-tuning adjusts the model weights on a narrow dataset [22], it is technically complex and requires retraining for updates. RAG, conversely, is less expensive, less time-consuming, and allows for the instant injection of the most trusted, up-to-date business data (e.g., real-time brand news or recent policy changes).[20, 22]
B. Best Practices for Corpus Hygiene (The RAG Failure Point)
The reliability of a RAG system is directly proportional to the quality and structure of its input documents, known as "corpus hygiene." Simply indexing large, unstructured documents is an anti-pattern that leads to low-quality retrieval.[23]
1. Document Structuring and Chunking
• Structure: Documents must be cleaned and organized. Utilizing clear headings and subheadings improves readability and helps RAG models understand the content hierarchy, enabling better indexing.[23]
• Chunking: Documents must be broken down into smaller, self-contained units for efficient retrieval.[23] Optimal chunk size is critical for maintaining context and semantic richness. Best practices suggest chunk sizes of approximately 800–1200 tokens with a 10–15% overlap.[24, 25] This size must be calibrated to work optimally across all models used in the pipeline (e.g., both summarization models and embedding models).[25]
2. Defining Proprietary Terminology
LLMs trained on public data will struggle with internal or proprietary language. To ensure accurate understanding of enterprise data and prevent hallucinations, the organization must explicitly set the context, define abbreviations, and avoid or clearly define company-specific terminology within the RAG context.[23]
C. Implementing Retrieval-First Policy and Citation Protocol
For enterprise-grade applications, the goal is not merely to retrieve information, but to produce auditable, traceable content. This requires an explicit "retrieval-first" instruction scaffold that prioritizes the custom corpus and mandates evidence logging.
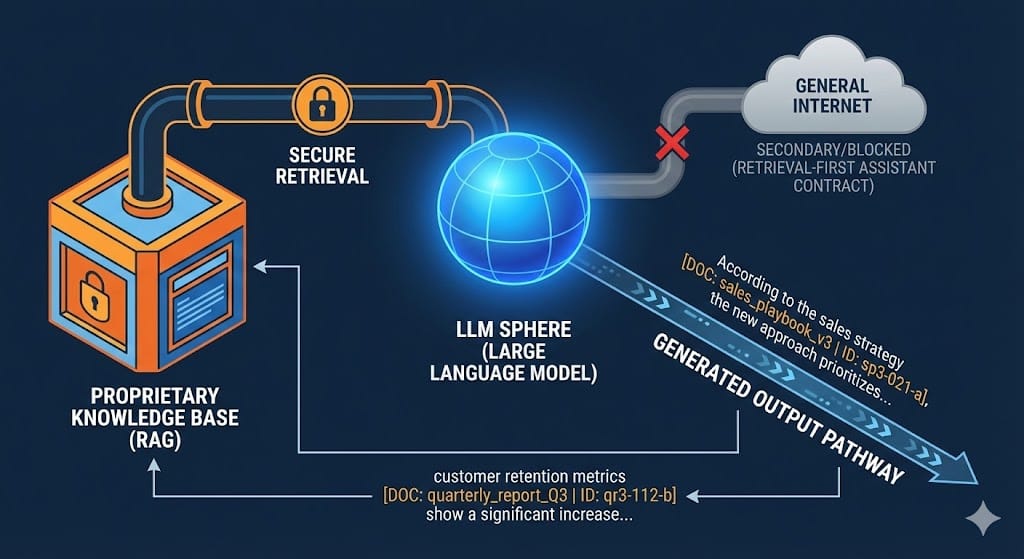
1. The Retrieval-First Assistant Contract
The system prompt must assign the LLM the role of a "Retrieval-First Assistant," explicitly instructing it that the uploaded corpus is primary and external knowledge is secondary.[24] The model must read a Doc Manifest, create a lightweight working index, and formulate search intents before selecting relevant documents.[24]
2. Mandatory Corpus Indexing and Citation
To enable auditing and citation, documents must have structural stability. Every chunk must be prefixed with a stable, machine-readable header containing the document, section, and a unique ID.[24]
A suggested header format is: DOC: sales_playbook_v3.md | SEC: 2.1 Cold Openers | ID: sp3-021-a.[24]
The most essential instruction for traceability is the mandate that the LLM must synthesize the answer from retrieved quotes first, and for each key claim, the model must cite the source using the stable ID format: (DOC:…, SEC:…, ID:…).[24, 26]This requirement for mandatory citation elevates RAG from a basic informational lookup tool to an auditable evidence system. By forcing the model to prove its claims by linking to the stable ID, the organization gains a direct method for measuring Context Adherence [19]—detecting if the information in the response was actually grounded in the provided context, or if the model hallucinated or used external priors.
3. The CORPUS-GAP Protocol
A crucial guardrail for high-stakes applications is defining the failure mode when the corpus is insufficient. The LLM should be instructed that if the required information is missing, it must state "CORPUS-GAP" and either ask for the missing data or proceed with a best-practice labeled as OUTSIDE-CORPUS.[24] This protocol actively prevents the model from attempting to fill knowledge gaps with general, potentially incorrect, or off-brand information from its training data.
V. Comparative Analysis of LLM Vendor Behavior
Achieving predictable, brand-consistent outputs at scale depends heavily on how the underlying Large Language Model architecture handles conflicting directives and long context windows. The instruction adherence capabilities of OpenAI, Anthropic, and Google exhibit significant differences that dictate enterprise deployment strategy.
A. The Instruction Hierarchy Challenge (IH)
The Instruction Hierarchy (IH) is the internal mechanism by which an LLM prioritizes various sources of instructions: built-in system safety policies, developer-level goals (System Prompt), and the user’s immediate prompt.[27, 28]
Current LLMs often face a security challenge because they treat every input, regardless of source (system vs. user), as plain text, failing to distinguish between instructions to follow versus user data to process.[28] This is analogous to a SQL injection vulnerability and makes models susceptible to prompt-injection attacks intended to subvert higher-priority system or safety constraints.[28] Testing how well a model follows this instruction hierarchy—for example, asking it to act as a math tutor (system goal) while simultaneously trying to "jailbreak" it into revealing the answer (user goal)—is a crucial evaluation metric for ensuring model alignment and robustness.[27, 29]
B. Architectural Differences in Instruction Adherence
The major LLM vendors have distinct architectural approaches that influence their adherence, consistency, and tool-use efficiency.
Criterion | OpenAI (GPT) | Anthropic (Claude) | Google (Gemini) |
Instruction Adherence | High, flexible, strong in tool integration.[30, 31] Reliable for complete, functional delivery.[32] | Excellent, noted for consistency and robust adherence to system constraints and safety designations.[31, 33] | High, strong focus on integrated context understanding and clear prompt design patterns.[33, 34] |
Context Management | Traditional; relies heavily on developer context engineering (e.g., external summarization) to prevent fidelity degradation. | Advanced Context Engineering, employs internal summarization/compaction to maintain fidelity in long contexts and multi-turn interactions.[4] | Strong in multimodal context injection (audio/video processing).[31] |
Tool/Function Calling | Superior. Advanced, efficient function calling, including parallel tool calls (can perform multiple lookups at once).[30, 31] | Sequential. Tool use is often more rigid, requiring explicit back-and-forth guidance for multi-step actions, increasing token count and latency.[30] | Strong multimodal capabilities, including inline Code Execution which increases robustness and potentially saves cost.[31] |
Best-Fit Persona Analogy | Reliable junior developer who needs supervision for functional correctness.[32] | Senior developer who excels in complex development with advanced functionality and strong compliance.[32] | Talented designer (ideal for MVPs/visuals) but may introduce bugs in iteration.[32] |
1. Tool Use and Operational Efficiency
A critical distinction lies in tool-use architecture. OpenAI provides advanced function calling features, notably the ability to call multiple tools or functions (such as RAG lookups) simultaneously (parallel tool calls).[30, 31] This capability dramatically improves operational efficiency and reduces latency in complex agentic workflows where multiple pieces of evidence must be gathered to synthesize a response.
In contrast, Anthropic's tool use is often more rigid or sequential, requiring a guided back-and-forth conversation with the model to achieve multi-step actions.[30] This sequential approach adds delays and increases transactional cost due to higher token consumption.[30]
The choice between these two platforms, therefore, represents a strategic alignment between priorities: OpenAI favors flexibility, speed, and cost efficiency in tool-heavy agent applications, while Anthropic’s compliance-first architecture justifies a premium for superior consistency and reliability, particularly in complex, long-document review tasks.[30, 35]
2. Instruction Fidelity and Long Context
While all vendors have expanded context windows, model performance and instruction fidelity can degrade drastically when extremely long prior context is present.[36] This is due to the inherent constraints of the LLM’s finite attention budget.[4]Anthropic has addressed this through a focus on Context Engineering, implementing strategies like message history summarization and compression. This process involves using the model itself to distill the context window in a high-fidelity manner, preserving critical architectural decisions or key details while discarding redundant information. This proactive compaction maintains performance consistency across multi-turn interactions and long documents.[4]
VI. Operationalizing and Monitoring Brand Voice
The final stage in establishing a high-quality content generation pipeline involves continuous iteration, systematic evaluation, and strategic governance.
A. Prompt Iteration and Experimentation
Prompt design is an iterative process; the optimal prompt is rarely achieved on the first attempt.[34, 37] Organizations must adopt a culture of continuous experimentation, trying different phrasings and adjusting model parameters to elicit the best creative or consistent output.[37]A formal feedback loop must be established where the AI’s outputs are used to inform future prompts.[37] Furthermore, because prompts function as high-value intellectual property and code assets, utilizing robust prompt management platforms or version control systems streamlines testing, adjustments, and collaboration, ensuring that revisions are tracked and quality control is maintained.[10]
B. Establishing AI Governance and Review Loops
Governance relies on measuring model behavior against both proprietary knowledge (RAG data) and explicit instructions (System Prompt).1. Context Adherence vs. Instruction Adherence
Effective evaluation requires differentiating between two key metrics [19]:
• Context Adherence (Grounding): Detects instances where the model stated information not included in the provided RAG context.[19] Low Context Adherence signals hallucination or reliance on external, non-proprietary knowledge, indicating a failure in the RAG pipeline or the model's grounding fidelity.
• Instruction Adherence: Detects instances where the model failed to follow the steps or behavioral constraints defined in its prompt, such as style, tone, or procedural requirements ("first do Y, then do Z").[19]
Low Instruction Adherence suggests prompt contradictions or insufficient steerage.
2. RAG Evaluation Strategy
Because RAG systems involve complex pipelines (retrieval, chunking, search, generation), evaluation must be systematic to identify failure points.[38] This involves separate evaluations for both core components:
• Retrieval Quality: Assessing how well the system finds relevant context, often measured using relevance scoring or recall metrics.[38]
• Generation Quality: Assessing the response based on faithfulness to the retrieved context (Context Adherence), completeness, and adherence to required stylistic or structural qualities (Instruction Adherence).[19, 38]
To bootstrap the evaluation process, LLMs can be utilized to generate synthetic test data—realistic question-answer pairs derived from the corpus—which allows for stress-testing the RAG system’s robustness before production deployment.[38]
C. Operationalizing the Context Engineering Playbook
The decision to adopt a system-level content strategy must incorporate a refined view on resource allocation, balancing the cost and time associated with different grounding techniques.
• RAG vs. Fine-Tuning Strategy: RAG should be utilized for dynamic, frequently updated knowledge bases (e.g., brand news, immediate policy changes).[2, 20] Fine-tuning should be reserved only for scenarios requiring highly specific, baked-in structural style across very high-volume, tightly scoped formats, where the cost and time investment can be justified by the need for minimal output variability.[2]
VII. Conclusions and Recommendations
Achieving non-generic, high-quality, and brand-consistent content is an architectural challenge, solved not by a single prompt, but by robust Context Engineering. The strategy must move beyond simple instruction sets to a structured scaffolding that governs the LLM's identity, behavior, and knowledge consumption.A. Key Prescriptive Recommendations
1. Mandate Context Engineering via System Prompts: Establish a System Prompt that utilizes Separation of Concerns (SoC) architecture, clearly delineating the AI's functional role (Role Prompting) from its stylistic behavior (Persona Specification). Explicitly forbid internal prompt contradictions to maintain Instruction Adherence.[7]
2. Govern the Style Void with Negative Prompting: Actively combat the model’s generic default by establishing a comprehensive dictionary of style-oriented negative prompts. This is necessary to suppress filler phrases, jargon, and stylistic anti-patterns that flatten brand voice.[3, 18]
3. Build an Auditable RAG Pipeline: For all content based on proprietary brand guidelines or policies, RAG is the required grounding mechanism. Implement strict Corpus Hygiene rules, including stable indexing of documents (e.g., chunks of 800–1200 tokens with 10–15% overlap, prefixed with IDs).[24, 25]
4. Enforce Traceability with Citation Protocol: Institute a "Retrieval-First Assistant" contract and mandate that the LLM cite all key claims using stable ID headers (DOC:…, SEC:…, ID:…). This transforms the RAG output into an auditable evidence log, allowing for quantitative verification of Context Adherence.[19, 24] The explicit use of the CORPUS-GAP protocol is mandatory to prevent unbounded hallucination.
B. Vendor Selection Based on Architectural Priorities
The choice of foundation model platform must align with core organizational priorities, recognizing the fundamental differences in instruction hierarchy and tool architecture:
• For High Consistency and Compliance: Anthropic (Claude) is the recommended choice. Its architecture prioritizes consistency and robust adherence to system constraints, making it ideal for tasks involving detailed long-document review (legal, financial) where the highest fidelity is required, despite potentially higher latency in complex tool-use workflows.[30, 35]
• For Agentic Efficiency and Flexibility: OpenAI (GPT) is recommended where complex multi-step workflows are common. Its superior parallel function calling capability reduces latency and operational token cost compared to sequential approaches, offering greater speed and flexibility in general-purpose and creative applications.[30, 31]
• For Multimodal Integration: Google (Gemini) is the primary choice when the content pipeline frequently involves processing or generating content based on audio, video, or rich visual data.[31]
Sources
1. Prompt engineering techniques - Azure OpenAI | Microsoft Learn, https://learn.microsoft.com/en-us/azure/ai-foundry/openai/concepts/prompt-engineering?view=foundry-classic
2. Maintaining Brand Voice With Generative AI | by Foresight Fox | Nov, 2025 | Medium, https://medium.com/@ffxcontent/maintaining-brand-voice-with-generative-ai-cca9273d4081
3. Most Commonly/Frequently Used Words by LLMs : r/ChatGPTPro - Reddit, https://www.reddit.com/r/ChatGPTPro/comments/1bvdvt1/most_commonlyfrequently_used_words_by_llms/
4. Effective context engineering for AI agents - Anthropic, https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents
6. User prompts vs. system prompts: What's the difference? - Regie.ai, https://www.regie.ai/blog/user-prompts-vs-system-prompts
7. The Art of Writing Great System Prompts | by Saurabh Singh - Medium, https://medium.com/towardsdev/the-art-of-writing-great-system-prompts-abb22f8b8f37
8. Role-Prompting: Does Adding Personas to Your Prompts Really Make a Difference?, https://www.prompthub.us/blog/role-prompting-does-adding-personas-to-your-prompts-really-make-a-difference
9. Role Prompting & Persona Specification: Tailoring AI Responses - Paradiso Solutions, https://www.paradisosolutions.com/blog/role-prompting-and-persona-specification/
10. How Examples Improve LLM Style Consistency - Ghost, https://latitude-blog.ghost.io/blog/how-examples-improve-llm-style-consistency/
11. What is few shot prompting? - IBM, https://www.ibm.com/think/topics/few-shot-prompting
12. Prompting Techniques | Prompt Engineering Guide, https://www.promptingguide.ai/techniques
13. Combining Prompting Techniques, https://learnprompting.org/docs/basics/combining_techniques
14. arXiv:2307.05300v4 [cs.AI] 26 Mar 2024, https://blender.cs.illinois.edu/paper/lmcollaboration2024.pdf
15. What is a Negative Prompt in AI? - AirOps, https://www.airops.com/blog/what-is-a-negative-prompt-in-ai
16. Mastering AI with negative prompts for creators - Artlist Blog, https://artlist.io/blog/negative-prompts/
18. How to Use AI Negative Prompts for Better Outputs (+Examples) - ClickUp, https://clickup.com/blog/ai-negative-prompt-examples/
19. Context vs. Instruction Adherence | Guardrail Metrics FAQ - Galileo, https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-guardrail-metrics/faq/context-adherence-vs-instruction-adherence
20. AI Brand Voice Generator for Consistent Messaging | Acrolinx, https://www.acrolinx.com/blog/does-your-ai-speak-your-brand-voice/
21. What is LLM grounding? - Iguazio, https://www.iguazio.com/glossary/llm-grounding/
22. LLM Grounding Leads to More Accurate Contextual Responses - K2view, https://www.k2view.com/blog/llm-grounding/
23. Documentation best practices for RAG applications - AWS Prescriptive Guidance, https://docs.aws.amazon.com/prescriptive-guidance/latest/writing-best-practices-rag/best-practices.html
24. Prompting mainstream LLM's for enhanced processing of uploaded ..., https://www.reddit.com/r/PromptEngineering/comments/1o5k1fb/prompting_mainstream_llm%27s_for_enhanced_processing_of_uploaded_reference_material/
25. Common retrieval augmented generation (RAG) techniques explained | The Microsoft Cloud Blog, https://www.microsoft.com/en-us/microsoft-cloud/blog/2025/02/04/common-retrieval-augmented-generation-rag-techniques-explained/
26. Prompting mainstream LLM's for enhanced processing of uploaded reference material/dox/project files??? : r/PromptEngineering - Reddit, https://www.reddit.com/r/PromptEngineering/comments/1o5k1fb/prompting_mainstream_llms_for_enhanced_processing/
27. Findings from a pilot Anthropic–OpenAI alignment evaluation exercise: OpenAI Safety Tests, https://openai.com/index/openai-anthropic-safety-evaluation/
28. Reasoning Up the Instruction Ladder for Controllable Language Models - arXiv, https://arxiv.org/html/2511.04694v3
29. OpenAI and Anthropic evaluated each others' models - which ones came out on top | ZDNET, https://www.zdnet.com/article/openai-and-anthropic-evaluated-each-others-models-which-ones-came-out-on-top/
30. OpenAI API vs Anthropic API: The 2025 developer's guide - eesel AI, https://www.eesel.ai/blog/openai-api-vs-anthropic-api
31. AI API Comparison 2024: Anthropic vs Google vs OpenAI - Big-AGI, https://big-agi.com/blog/ai-api-comparison-2024-anthropic-vs-google-vs-openai
32. The AI Code Generator Battle: Google Gemini vs OpenAI vs Anthropic on Lovable - Medium, https://medium.com/@kyralabs/the-ai-code-generator-battle-google-gemini-vs-openai-vs-anthropic-on-lovable-50315d0d5934
33. LLM Provider Prompt Comparison: OpenAI vs. Anthropic vs. Google Guide - Media & Technology Group, LLC, https://mediatech.group/prompt-engineering/llm-provider-prompt-comparison-openai-vs-anthropic-vs-google-guide/
34. Prompt design strategies | Gemini API | Google AI for Developers, https://ai.google.dev/gemini-api/docs/prompting-strategies
35. OpenAI vs. Anthropic vs. Google Gemini: The enterprise LLM platform guide - Xenoss, https://xenoss.io/blog/openai-vs-anthropic-vs-google-gemini-enterprise-llm-platform-guide
36. Evaluating the Sensitivity of LLMs to Prior Context - arXiv, https://arxiv.org/html/2506.00069v1
37. Enhancing LLM Creativity with Advanced Prompt Techniques - Media & Technology Group, LLC, https://mediatech.group/prompt-engineering/enhancing-llm-creativity-with-advanced-prompt-techniques/
38. A complete guide to RAG evaluation: metrics, testing and best practices - Evidently AI, https://www.evidentlyai.com/llm-guide/rag-evaluation